Abstract
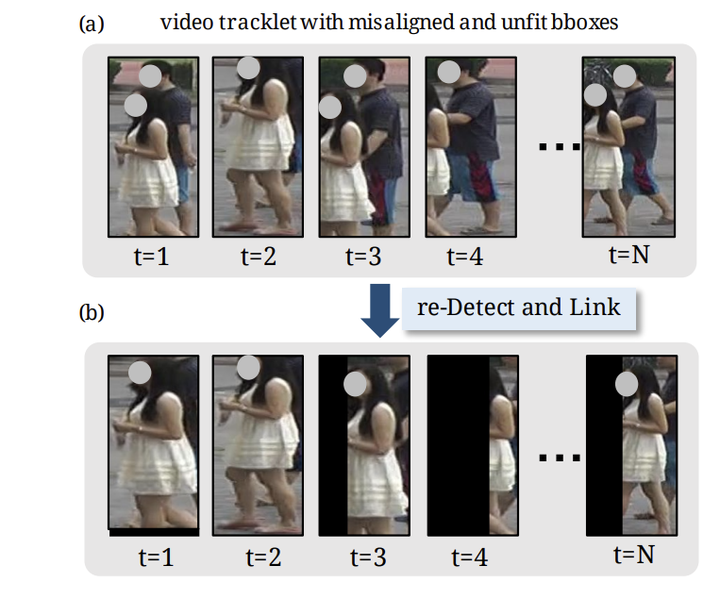
Video-based person re-identification (Re-ID) aims at matching the video tracklets with cropped video frames for identifying the pedestrians under different cameras. However, there exists severe spatial and temporal misalignment for those cropped tracklets due to the imperfect detection and tracking results generated with obsolete methods. To address this issue, we present a simple re-Detect and Link (DL) module which can effectively reduce those unexpected noise through applying the deep learning-based detection and tracking on the cropped tracklets. Furthermore, we introduce an improved model called Coarse-to-Fine AxialAttention Network (CF-AAN). Based on the typical Nonlocal Network, we replace the non-local module with three 1-D position-sensitive axial attentions, in addition to our proposed coarse-to-fine structure. With the developed CFAAN, compared to the original non-local operation, we can not only significantly reduce the computation cost but also obtain the state-of-the-art performance (91.3% in rank1 and 86.5% in mAP) on the large-scale MARS dataset. Meanwhile, by simply adopting our DL module for data alignment, to our surprise, several baseline models can achieve better or comparable results with the current stateof-the-arts. Besides, we discover the errors not only for the identity labels of tracklets but also for the evaluation protocol for the test data of MARS. We hope that our work can help the community for the further development of invariant representation without the hassle of the spatial and temporal alignment and dataset noise. The code, corrected labels, evaluation protocol, and the aligned data will be available at https://github.com/jackie840129/CF-AAN