Spatially and Temporally Efficient Non-local Attention Network for Video-based Person Re-Identification
Abstract
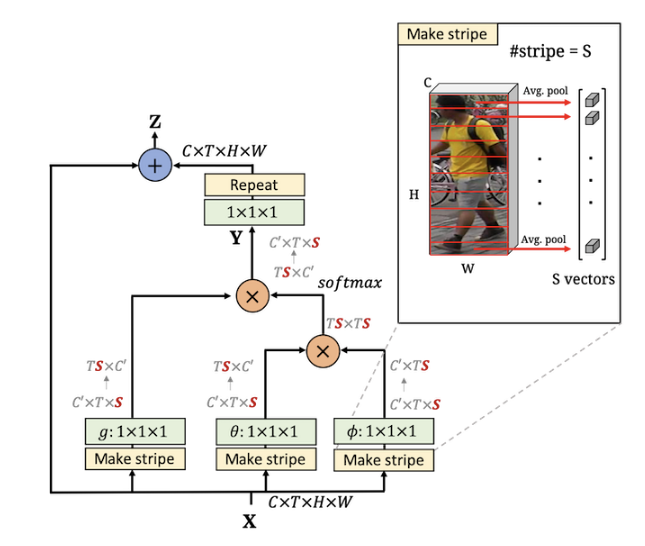
Video-based person re-identification (Re-ID) aims at matching video sequences of pedestrians across non-overlapping cameras. It is a practical yet challenging task of how to embed spatial and temporal information of a video into its feature representation. While most existing methods learn the video characteristics by aggregating image-wise features and designing attention mechanisms in Neural Networks, they only explore the correlation between frames at high-level features. In this work, we target at refining the intermediate features as well as high-level features with non-local attention operations and make two contributions.(i) We propose a Non-local Video Attention Network (NVAN) to incorporate video characteristics into the representation at multiple feature levels.(ii) We further introduce a Spatially and Temporally Efficient Non-local Video Attention Network (STE-NVAN) to reduce the computation complexity by exploring spatial and temporal redundancy presented in pedestrian videos. Extensive experiments show that our NVAN outperforms state-of-the-arts by 3.8% in rank-1 accuracy on MARS dataset and confirms our STE-NVAN displays a much superior computation footprint compared to existing methods.